
Perspective on Risk - June 11, 2022
Perspective on Risk - June 11, 2022
A Personal Appeal; Stepping Back - Technology is Still Deflationary
A Personal Appeal
Many of you know that I volunteer at a Mission that helps feed the needy. They are currently running a fundraiser to rebuild their community kitchen, that was damaged when the sprinkler system flooded the structure.
I don’t charge for this newsletter; if you’ve found it valuable and have a few coins in the pocket, please consider clicking through and donating - $5 or $50,000, every dollar helps.
HHRM Community Kitchen Giving Page


Stepping Back - Technology is Still Deflationary
We can get lost in the day-to-day debates about ‘transitory’ inflation shocks. But the longer-term trend will continue to be driven, in large part, by technological progress.
When I was at AIG, for a number of years I published the H3 Newsletter, which predominantly looked at technology that was likely to change the world by significantly reducing marginal costs. We looked at solar, batteries, CRISPR, robotics, etc. I thought I’d take an updated look at a few of those trends. Alec Stapp linked to four charts illustrating progress on Moore’s law, the price of solar, the price of sequencing genes, and the price of lithium-ion batteries. As you can see, all four continue to show exponential increases in capacity per dollar.
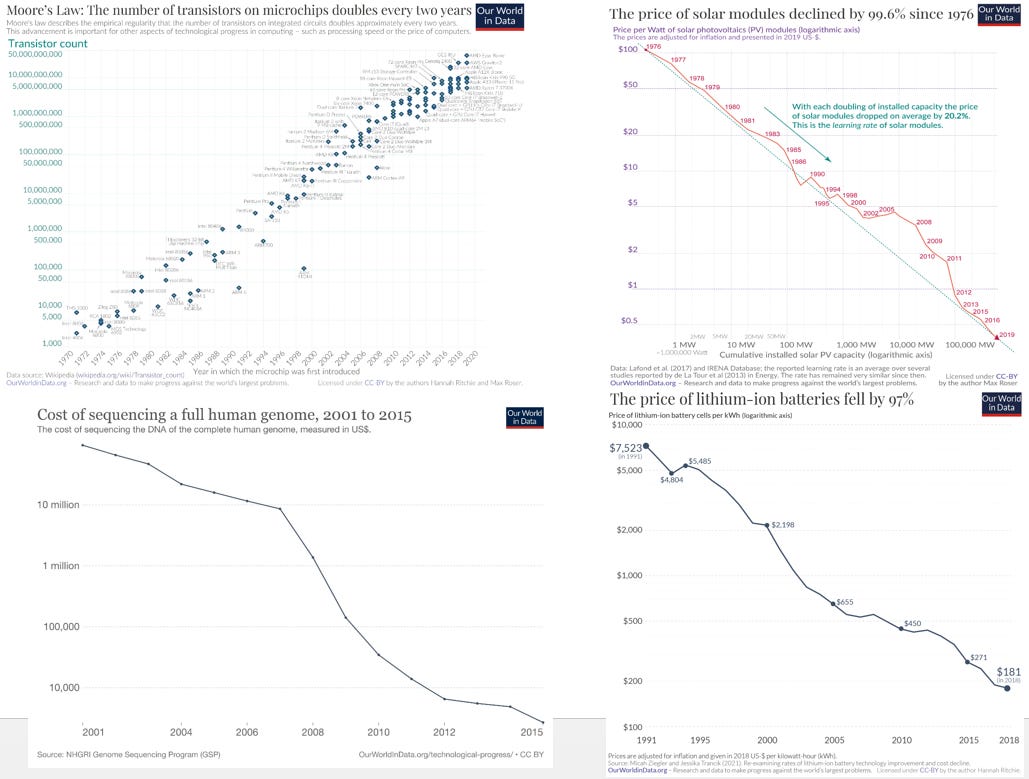
How have these trends affected us?
Let’s look at artificial intelligence. Alan Turing is regarded as kicking off the quest for artificial intelligence with his 1950 paper Computing Machinery and Intelligence wherein he asks the fundamental question “Can Machines Think?” Eight years later, Frank Rosenblatt first implemented a perceptron, which essentially was a linear classifier. While numerous other technical developments occurred in the intervening years, Geoffrey Hinton and his co-authors popularized the concept of back-propagation for the training of multi-layer neural networks in 1986. Still, it was not until 2012, when Hinton and his students significantly outperformed other models in the ImageNet competition that wider awareness of the advancement occurred. Their winning model, AlexNet, contained 60 million parameters and 500,000 neurons, organized into eight (8) layers, trained on 1.3 million high-resolution (still) images, and was an early model (though not the first) to be trained and run on GPUs.
There has been one other fundamental development, that only occurred five years ago: that is, the development and use of Transformers and Attention. Vaswani, et. al. authored a paper Attention is all you need.1 Their approach “propose a new simple network architecture, the Transformer, based solely on attention mechanisms …” that replaces many other approaches that are more recursive and that require greater computational ability.
So where are we now?
GPT-3, the state-of-the-art language model, was introduced in 2020. GPT-3 has 175 billion parameters, and was trained on 410 billion Common Crawl tokens, as well as 67 billion books. GPT-3 was estimated to have cost $10-20million to train. GPT-4 is expected to have 100 trillion parameters2 and be 500x the size of GPT-3.3 The New York Times described GPT-3's capabilities as being able to write original prose with fluency equivalent to that of a human.4 GPT-3 is writing and explaining computer code, chatbots, and language translation.

DALL-E 2 is an artificial intelligence program that creates images from textual descriptions. It uses a 3.5-billion parameter model to interpret natural language inputs and generate corresponding images while using another 1.5-billion parameter model to enhance the resolution of its digitally-produced images. It was trained on 400 million pairs of images and text.5





Of course, someone had a chat with GPT-3 about Dalle-e.

If you’d like to try out a smaller version, Dall-e mini, click here and generate your own picture. Not quite as sophisticated as the big brother.
Alphafold 26 is perhaps the most advanced usage of machine learning.
“In November 2020, a team of AI scientists from Google DeepMind indisputably won the 14th Critical Assessment of Structural Prediction competition, a biennial blind test where computational biologists try to predict the structure of several proteins whose structure has been determined experimentally but not publicly released. Their results were so astounding, and the problem so central to biology, that it took the entire world by surprise and left an entire discipline, computational biology, wondering what had just happened.7
GPT-3, Dall-e 2 and Alphafold all use transformers and a form of self-attention.
So in a decade, we have gone from being able to identify a cat in a picture, to generating cats in Prussian gear eating lasagna, to solving some of the most difficult problems in medicine.
Solar and wind power are now the lowest cost energy source. In Norway in 2021, close to eight in 10 new passenger vehicles sold in the country were all-electric. Three SpaceX boosters have now been reused a dozen times each, dramatically lowering the cost of spaceflight. SpaceX has successfully landed 99 out of 104 (95.2%) for the Falcon 9 Block 5 version. Multiple companies are now deploying large fleets of low-earth-orbit satellites. Drones have changed the case of warfare, and are delivering medicine in Africa. 5G is massively expanding bandwidth enabling the internet-of-things.
An attention-based system is thought to consist of three components:
A process that “reads” raw data (such as source words in a source sentence), and converts them into distributed representations, with one feature vector associated with each word position.
A list of feature vectors storing the output of the reader. This can be understood as a “memory” containing a sequence of facts, which can be retrieved later, not necessarily in the same order, without having to visit all of them.
A process that “exploits” the content of the memory to sequentially perform a task, at each time step having the ability put attention on the content of one memory element (or a few, with a different weight).
– Page 491, Deep Learning, 2017.
For reference, the human brain is estimated to have 80 billion neurons and up to 400 trillion parameters
New York Times, A.I. Is Mastering Language. Should We Trust What It Says?
Oxford Protein Informatics Group, AlphaFold 2 is here: what’s behind the structure prediction miracle